Stopping Automated Attack Tools
An analysis of web-based application
techniques capable of defending against current and future automated
attack tools
For an increasing number of organisations,
their web-based applications and content delivery platforms
represent some of their most prized and publicly visible business
assets. Whether they are used to provide interactive customer
services, vital client-server operations, or just to act as
informational references, these assets are vulnerable to an
increasing number of automated attack vectors – largely due to
limitations within the core protocols and insecure application
development techniques.
As these web-based applications become larger
and more sophisticated, the probability of security flaws or
vulnerabilities being incorporated into new developments has
increased substantially. In fact, most security conscious
organisations now realise that their web-based applications are the
largest single source of exploitable vulnerabilities.
Over recent years the ability to discover and
identify these application flaws has become a critical assessment
phase for both professional security agencies and would-be
attackers. To increase the speed and reliability of identifying
application-level vulnerabilities and potential exploitation
vectors, both groups make extensive use of automated scanning tools.
These automated scanning tools are designed to
take full advantage of the state-less nature of the HTTP protocol
and insecure development techniques by bombarding the hosting server
with specially crafted content requests and/or data submissions.
Depending upon the nature of the scanning product its purpose may be
to create a duplicate of the client-visible content (e.g. content
mirroring); search for specific content (i.e. administrative pages,
backup files, e-mail addresses for spam); fuzz application variables
to elicit server errors and uncover exploitable holes (e.g. SQL
injection, cross-site scripting), or even to conduct a brute force
discovery of hidden content or customer authentication credentials.
While there are a vast number of defensive
strategies designed to help protect a web-based application against
actual exploitation, very few of these strategies provide adequate
defence against the initial phases of an attack – in particular the
high dependency upon automated scanning tools.
By adopting a number of simple design criteria
and/or incorporating minor code changes to existing applications,
many organisations will find that the current generation of
application scanning tools are ineffective in the discovery of
probable security flaws; thereby helping reduce the likelihood for
future exploitation.
Automated Scanning
Given the size and complexity of modern
web-based applications, the use of automated scanners to navigate,
record and test for possible vulnerabilities has become a vital
stage in confirming an application’s security. Without the use of
automated scanning tools, the process of discovering existing
security vulnerabilities is an extremely time consuming task and,
when done manually, dependant upon the raw skills of the security
consultant or attacker.
Therefore, automated scanning tools are a key component in any
attacker’s arsenal – particularly if they wish to identify and
exploit a vulnerability with the least amount of effort and within
the shortest possible timescale.
Developments in Automated Scanning
Just as web-based applications have evolved
over the past decade, so too have the automated tools used to scan
and uncover potential security vulnerabilities. Whilst the vast
majority of these tools and techniques have come from non-commercial
and “underground” sources, the quality of the tools is generally
very high and they are more than capable of discovering
vulnerabilities in most current application developments and/or
deployments.
These automated scanning tools have undergone
a series of evolutionary steps in order to overcome the security
benefits of each advance in web-development technology, and can be
divided into a small number of technological groupings or
“generations”.
This evolution of automated scanning tools can
be quickly condensed into the following “generations”:
- 1st Generation – The first generation of
automated application scanners did no processing or
interpretation of the content they attempted to retrieve. These
tools would typically use lists of known file locations (e.g.
file locations associated with common IIS administration pages,
Compaq Insight Manager pages, Apache root paths, etc.) and
sequentially request each URL. At the end of the scan, the
attacker would have a list of valid file locations that could
then be investigated manually. A common example of a 1st
generation tool is a CGI Scanner.
- 2nd Generation – The 2nd generation of
automated scanners used a form of application logic to identify
URL’s or URL components contained within an HTML-based page
(including the raw client-side scripting content) and navigate
to any relevant linked pages – repeating this process as they
navigate the host content (a process commonly referred to as
‘spidering’ or ‘spydering’). Depending upon the nature of the
specific tool, it may just store the content locally (e.g.
mirroring), it may inspect the retrieved content for key values
(e.g. email addresses, developer comments, form variables,
etc.), build up a dictionary of key words that could be used for
later brute forcing attacks, or compile a list of other metrics
of the application under investigation (e.g. error messages,
file sizes, differences between file contents, etc.) for future
reference.
- 2.5 Generation – A slight advance over
second generation scanners, this generation of scanners made use
of a limited ability to reproduce or mimic the applications
presentation layer. This is typically accomplished by the tool
memorising a number of default user clicks or data submissions
to get to a key area within the application (e.g. logging into
the application using valid credentials) and then continuing
with standard 1st or 2nd generation tool processes afterwards.
Automated scanning tools that utilise this approach are commonly
used in the load or performance testing of an application. Also
included within this generational grouping are scanning tools
that can understand “onclick” events that build simple URL’s.
- 3rd Generation – 3rd generation scanning
tools are capable of correctly interpreting client-side code
(whether that be JavaScript, VBscript, Java, or some other ”just
in time” interpreted language) as if rendered in a standard
browser, and executing in a fashion similar to a real user.
Whilst there are literally thousands of tools that can be
classed as 1st, 2nd or even 2.5 generation, there are currently
no reliable 3rd generation scanning tools capable of correctly
interpreting client-side code without a great deal of
customisation or tuning for the specific web-technology
application under investigation.
What is an automated scanner?
As far as web-based applications are
concerned, there are a number of methods and security evaluation
techniques that can be used to uncover information about an
application that has a security context. An automated scanner makes
use of one or more discovery techniques to request data and scans
each page returned by the web server and attempts to categorise or
identify relative information.
Within the security sphere, in the context of an attack, the key
functions and discovery techniques that can be automated include the
following:
- Mirroring – The attacker seeks to capture
or create a comprehensive copy of the application on a server or
storage device of their choosing. This mirrored image of the
application content can be used for:
Theft and repackaging of intellectual property.
Part of a customer deception crime such as man-in-the-middle
attacks, Phishing, or identity theft.
- Site Scraping or Spidering – The
attacker’s goal is to analyse all returned data and uncover
useful information within the visible and non-visible sections
of the HTML or client-side scripts. Information gleaned in this
process can be used for:
Harvesting of email addresses for spam lists.
Social engineering attacks based upon personal data (such as
names, telephone numbers, email addresses, etc.)
Ascertaining backend server processes and software versions or
revisions.
Understanding development techniques and possible code bypasses
based upon “hidden” comments and notes left behind by the
application developer(s).
Uncovering application details that will influence future phases
in the exploitation of the application (e.g. references to
“hidden” URL’s, test accounts, interesting content, etc.).
Mapping the structure of application URLs and content
linking/referencing.
- CGI Scanning – The inclusion of
exhaustive lists of content locations, paths and file names to
uncover existing application content that could be used in later
examinations or for exploitation. Typically, the information
being sought includes:
Likely administrative pages or directories.
Scripts and controls associated with different web servers and
known to be vulnerable to exploitation.
Default content and sample files.
Common “hidden” directories or file path locations.
Shared web services or content not directly referenced by the
web-based application.
File download repository locations.
Files commonly associated with temporary content or backup
versions.
- Brute Forcing – Using this technique, an
attacker attempts to brute force guess an important piece of
data (e.g. a password or account number) to gain access to
additional areas or functionality within the application. Common
techniques make use of:
Extensive dictionaries.
Common file or directory path listings.
Information gathered through site scraping, spidering and CGI
scanning.
Hybrid dictionaries that include the use of common obfuscation
techniques such as elite-speak.
Incremental iteration through all possible character
combinations.
- Fuzzing – Closely related to brute
forcing, this process involves examining each form or
application submission variable for poor handling of unexpected
content. In recent years, many of the most dangerous application
security vulnerabilities have been discovered using this
technique. Typically each application variable is tested for:
Buffer overflows,
Type conversion handling,
Cross-site scripting,
SQL injection,
File and directory path navigation,
Differences between client-side and server-side validation
processes.
Automated Tool Classes
When discussing automated application scanning
and security tools, the most common references or classes for
breakdown are:
- Web Spider – any tool that will spider,
scrape or mirror content. Search engines can often be included
within this grouping.
- CGI Scanner – any tool that uses a file
or path reference list to identify URL’s for future analysis or
attack.
- Brute Forcer – any tool capable of
repetitive variable guessing – usually user ID’s or passwords.
- Fuzzer – typically an added function to a
web spider or personal proxy tool which is used to iterate
through a list of “dangerous content” in an attempt to elicit an
unexpected error from the application. Any unexpected errors
would be manually investigated later with the purpose being to
extend the “dangerous content” into a viable attack vector.
- Vulnerability Scanner – most often a
complex automated tool that makes use of multiple vulnerability
discovery techniques. For instance the vulnerability scanner may
choose to use spidering techniques to map the application after
which it then inspects the HTML content to discover all data
submission variables and then proceeds to submit a range of
knowingly bad characters or content to elicit an unexpected
response – finally it attempts to classify any discovered
vulnerabilities.
Frequently Used Defences
Over the years a number of defences have been
experimented with in order to help protect against the use of
automated scanning tools. Most of the defensive research and
experimentation has been conducted by web sites that have to protect
against tools that capture the contents of the web application/site
(e.g. downloading of all images from a ‘porn’ site) or brute force
guessing customer login credentials.
The most 10 most frequently utilised defences
are:
- Renaming the server hosting software
- Blocking HEAD requests for content
information,
- Use of the REFERER field to evaluate
previous link information,
- Manipulation of Content-Type to “break”
file downloads,
- Client-side redirects to the real content
location,
- HTTP status codes to hide informational
errors,
- Triggering thresholds and timeouts to
prevent repetitive content requests,
- Single-use links to ensure users stick to
a single navigation path,
- Honeypot links to identify non-human
requests,
- Turing tests to block non-human content
requests.
Server Host Renaming
An early method of thwarting 1st generation
automated tools exploited their reliance upon the host server
version information. Application logic within these early tools made
use of a check to see exactly what type of web server they were
running against by reading the Server variable within the HTTP
headers and then using this information to select the most
appropriate list of checks it would then execute.

By changing the Server variable from one
server type/description to another (e.g. “Microsoft-IIS/5.0” becomes
“Apache/1.3.19 (Unix)”), this could often be enough to deceive the
tool and prevent it from discovering vulnerable CGI’s and URL’s.

Blocking of HEAD Requests
There are a number of legitimate methods in
which a client browser can request content from a web-based
application. The most common, GET and POST, are used to elicit a
response from the application server and typically receive
HTML-based content. If the client browser does not want to receive
the full content – but instead wishes to know whether a link exists
or that the content is unchanged for instance – it can issue a HEAD
request (with formatting almost identical to a GET request).
Many 1st generation automated scanners choose
to use HEAD requests to spider an application or identify vulnerable
CGI’s instead of GET requests because less data is transferred and
consequently the scanning or enumeration can be conducted at a
greater speed.
Defending against automated scanners that rely upon HEAD requests is
trivial. Almost all web hosting servers can be configured to not
respond to HTTP HEAD requests – and only provide content via an
approved list of HTTP options. This type of configuration is quite
common; however, there may be ramifications for data throughput
(this may increase as any content request must now retrieve the full
volume of data instead of just the file/page headers) and the number
of dropped connections may also increase (some tools, after
identifying that HEAD requests do not work, will use GET requests
and forcibly drop the connection once it has received the header
data within the GET response).

Use of the REFERER Field
One of the most popular methods of governing
access to the web applications content is often through the use of
the Referer entity-header field within the client browser’s
submitted HTTP header. Ideally, each time a client web browser
requests content or submits data, the HTTP header should contain a
field indicating the source URL from which the client request was
made. The application then uses this information to verify that the
users request has come via an approved path – delivering the
requested content if the referrer path is appropriate, or stopping
the request if the Referer field is incorrect or missing.
For instance, the user is browsing a content
page with a URL of http://www.example.com/IWasHere.html containing a
link to the page http://www.example.com/Next/ImGoingHere.html. By
clicking on the link, the user will make a HTTP request to the
server (www.example.com) containing the following headers:

The application must maintain a list (or use an algorithm) for
validating appropriate access paths to the requested content, and
will use the Referer information to verify that the user has indeed
come from a valid link. It is not uncommon to reduce the amount of
checking by restricting the check to verifying that it just contains
the same domain name – if not, the client browser is then redirected
to the sites main/initial/login page.
Many 1st and 2nd generation automated scanners
do not use (or update) the Referer field within the HTTP header of
each request. Therefore, by not processing content requests or
submissions with missing or inappropriate Referer data, the
application can often block these tools.
It is important to note that some browsers may
be configured to not submit a Referer field, or they may contain a
link or data of the user’s choice as a method of reducing any
leakage of personal information. Additionally, if the user follows a
link from another site (e.g. a search engine) or their saved
favourites, any content restrictions based upon Referer information
will also be triggered.

Content-Type Manipulation
Another method of preventing automated tools
from downloading vast amounts of site content is through the use of
Content-Type entity-header field manipulation.
The Content-Type field is typically used to
indicate the media type of the entity-body sent to the recipient or,
in the case of a HEAD request, the media type that would have been
sent had the request been a GET request. For example, in the
following request the Content-Type has been set by the server to be
text/html:

Alternatively, MIME Content-Type can be
defined within the actual content through META tags using the
HTTP-EQUIV attribute. Tags using this form are supposed to have the
equivalent effect when specified as an HTTP header, and in some
servers may be translated to actual HTTP headers automatically or by
a pre-processing tool.

The application server can define a MIME
Content-Type for each and every data object, and is normally used to
define how the client browser should interpret the data. There are
dozens of content types defined and in common usage, with more being
defined all the time. Some of the most frequently encountered
definitions include:

By altering file extensions and assigning them
non-default MIME types through the use of the servers Content-Type
response, it is often possible to trick 1st and 2nd generation
automated scanning tools into either ignoring application links or
misinterpreting the data they receive.
Automated web spiders and vulnerability
scanners are tuned to ignore files that do not contain HTML content
(e.g. GIF, JPG, PDF, AVI, DOC, etc.) and the majority of existing
tools do not analyse MIME information contained within server HTTP
headers. Therefore, for example, by renaming .HTML files to .JPG and
ensuring that the Content-Type remains “text/html”, a document
containing valid HTML content but called “ImGoingHere.jpg” will be
correctly rendered as a web page in a browser, but will be ignored
by an automated scanner.

HTTP Status Codes
The majority of users are familiar with the
common status codes “200 OK”, “302 Redirect” and “404 File Not
Found”. The HTTP protocol provides for a multitude of status codes
which a web server can select and send to the client browser
following a data connection or request. These status codes are
divided into the following 5 key groupings:

From an automated tools perspective, the “200
OK” status code is typically interpreted as a valid request was made
to the server (e.g. the page exists and the URL is correct), while
any other returned status code in the 4xx and 5xx groupings can be
used to ascertain whether the request was invalid or triggered a
server-side fault. Depending upon the nature of the automated tool,
a 5xx status response could be indicative that malicious content
insertion may be possible (e.g. SQL injection, unsigned integer
denial of service) and is worthy of manual investigation and further
attack.
For instance, a CGI scanner will cycle through
a list of known files and file paths – rapidly requesting content
from the web-based application server. If a “200 OK” is received,
the CGI scanner then reports to the attacker that the path or
vulnerable page/content exists. If a “404 Not Found” is received,
the scanner assumes that the content doesn’t exists and is therefore
not vulnerable to that attack vector – and most likely will not
report anything back to the attacker.
However, all modern HTTP web servers allow for
bespoke error handling and customisation of status code
representations. Consequently, a highly successful method of
defeating the usefulness of automated scanners is to always present
the same status code (i.e. “200 OK”) for every request – regardless
of whether the request was legitimate, requested non-existent
content, or generate an unknown server error. This means that the
automated scanner cannot base its findings on HTTP status codes, and
must then use some form of content inspection logic to analyse the
actual content of the HTML body instead.

Client-side Redirection
For many automated scanners, the process of
identifying a link or embedded URL is done by searching for relevant
“HREF=” references within the HTML content. However, there are a
number of alternative methods for indicating URL’s within the HTML
body of a server response.
A mechanism called “client-side redirection”
is commonly used to redirect browsers to the correct content
location after requesting invalid, nonexistent or recently moved
content. The most common non-scripted method is through the use of
the “Refresh” field (note that the “Refresh” field also allows for a
wait period before being automatically redirected). Just like the
“Content-Type” field, the “Refresh” field can be contained within
the HTTP header or used within an HTTP-EQUIV META tag; for example:

Or

To use client-side redirection as a protective
measure against automated scanners, the application developer must
ensure that each URL for (valuable) content is initially intercepted
by a page designed to automatically redirect the client browser to
the correct/real content. For additional security, the application
server could also enforce a minimum “wait” time before responding to
requests for the real content.
The effect on many automated scanning tools is
to induce a “200 OK” status code for each request – therefore having
many of the benefits described in the earlier section.

Thresholds and Timeouts
In applications where session ID’s are used to
maintain the state of a connection (e.g. uniquely track the user or
identify the fact that they have already successfully authenticated
themselves), it is also common practice to measure two key
interaction variables – the time and frequency of each request or
data submission.
Normally, by monitoring the elapsed time since
the last data submission, an application can “timeout” a session and
force the user to re-login if they have not used the application for
an extended period (e.g. an e-banking application that automatically
logs out the user after 5 minutes of inactivity). However, it is
also possible to monitor the time taken between data submissions –
thereby identifying whether an automated tool is processing URL’s at
a speed that is unattainable or unlikely for a legitimate human
user.
In addition, multiple requests for the same
application content using the same session ID can also be monitored.
This is commonly implemented as part of an authentication process
designed to identify brute force guessing attacks (e.g. repeated
guesses at the password associated with an email address on a free
web-mail application server) – typically tied to account lockout
and/or session cancellation. A similar process can be used to
identify repeated attempts to access or submit to the same URL (e.g.
a particular CGI or page) – as would occur during a fuzzing attack
using an automated tool.
Consider the following HTTP POST data
submission:

In this example we see one captured POST
submission to the application server. The attacker is fuzzing the
“Account” field of the “/Toys/IwantToBuy.aspx” page by repeatedly
trying different attack strings (e.g. ‘;--<H1> in this instance). We
know that it is the same attacker because all previous requests have
used the same session ID. To identify the attack, the application
server maintains a couple of extra data variables associated with
the session ID information in its backend database – in this case
“last requested URL” and a numeric counter. Each time the “last
requested URL” is the same, the counter is incremented. Once the
counter threshold is reached (e.g. 5 repeated requests), the session
ID is revoked and any subsequent data submissions using that session
ID are then ignored.
The use of thresholds and timeouts within an
application can prove to be successful against all generations of
automated scanner. However, once an attacker understands the limits
of these two mechanisms (i.e. how many times can he request the same
page, and how “slow” the requests need to be to pretend to be human)
the automated tools can often be configured to not trigger these
application responses.

Onetime Links
Related to the application logic utilised in
managing URL request and data submissions through the HTTP Referer
field, in some cases it is possible to assign a unique “referrer
value” to each page the client browser requests. This “referrer
value” is then used to manage the location of the user within the
application and identify any requests deemed to be out of order.
For instance, consider the online retailers
purchasing page /BuyStageOne.aspx?track=1104569 which
contains the following URL’s in the page content:

Each URL, including the users current
location, identifies a tracker variable (“track=”) with a numeric
value (initially “1104569”). If the user clicks on any link, this
tracker value will also be submitted to the application server. Now,
assuming that the user clicks on the last link to proceed with the
purchasing process, he will proceed to the page “BuyStageTwo.aspx”,
but will also be issued with a new unique tracker number and, for
example, the contents of the new page (e.g. /BuyStageTwo.aspx?track=1104570)
may also contain the following URL’s:

Key things to note with this onetime link
anti-scanner implementation are:
- The tracking number changes with each
page, and the earlier number is revoked so that it cannot be
used again by the user.
- Tracking numbers are bound to a per-user
session ID.
- Before the application will process any
page request or data submission, it must first verify the
integrity of the session (i.e. is the session ID real and make
sure it hasn’t been revoked) and then verify that the tracking
value is correct.
- Each URL or link, including the link
“back” to the previous page (/BuyStageTwo.aspx) has a new
tracking number. The default browser “back” and “forward”
buttons will not work – therefore this functionality must be
provided within the page itself.
- Any attempt to follow a URL without a
tracking number, or use an invalid tracking number, would be
handled by the application as either a user error or seen as an
attack (automated or otherwise).
- Although this example uses a sequential
increase in tracker numbers, this is not necessary and the
values could be random if required (the use of random tokens is
recommended).
- Whenever the user requests application
content containing the correct tracker number, the tracking
value can only be used once as a new value is assigned with the
server response.
This kind of implementation is successful
against most 1st and 2nd generation automated scanners. Many
Spidering and Mirroring tools parallelise their requests to speed up
the discovery/download process and would therefore fail to handle
the per-request changing tracking numbers. Fuzzers too would be
affected by this location state management system.
Note: whilst the examples above make use of URL’s containing
tracking numbers, the use of HTTP POST submissions instead of GET
requests are to be recommended. For a full discussion on the best
security practices for URL handling, readers are directed to the
paper “Host Naming and URL
Conventions” also written by the same author.

Honeypot Links
Since many scanning tools will automatically
identify URL’s within the HTML body of a page and blindly request
linked content, it is possible to include “hidden” links within an
applications content that will direct an automated tool to a
continually monitored page. Fake or monitored links such as these
fall under generic the category of “honeypots”. By embedding these
links within the HTML body in such a way that they would never be
visibly rendered or “clickable” by a human user, any client request
for this “hidden” content is most probably associated with an
attack.
For example, the following content extract
uses comment fields (i.e. <!-- and --> ) and background colours
(i.e. setting the link colour to be the same as the background
colour) to “hide” two URL’s that would not normally be followed by a
human user, but are typically followed by automated tools.

The web-based application would be designed in
such a way that automated responses (e.g. session ID cancellation,
automatic logoff, blocking of the attackers IP address, detailed
forensics logging, etc.) are initiated should any request be made to
access a honeypot link. Against standard automated scanners, the
most likely response is to issue a default page (e.g. the home page)
for all requests from that IP address or session ID – no matter what
the request is – and initiate any background investigative
processes.

Graphical & Audio Turing Tests
There are a number of ways in which the
application can force the user to interpret onscreen or audio
information, and submit a response that could not normally be
supplied through an automated process (unless you include
brute-force guessing) before proceeding into another section of the
application. The most common implementations make use of graphical
images containing a key word or value that cannot be discovered
using tools (such as OCR), but must be manually entered in to a form
field by the user.
For example, the following graphic is copied from the account
creation phase of the Microsoft Passport online service. The
background squiggles and leaning text is designed to help prevent
automated OCR (Optical Character Recognition) packages from
evaluating the text “597UTPH7”.

Unfortunately, graphics such as the one above
can be very difficult to understand for some people due to its
complexity or personal circumstances (e.g. colour blindness, failing
sight). Therefore, alternative Turing tests that make use of audio
sound bites can be used as an alternative. Microsoft’s Passport
registration also allows users to listen to a voice saying the pass
phrase which must be entered correctly to set up the account. To
make the process more difficult for automated dictation tools, some
background noises and hisses may be included with the real pass
phrase data. An example of Microsoft Passport support for a
voice-based Turing test is shown below.

This kind of user identification testing is
typically used at key points within high-volume applications (e.g.
popular webmail services, online domain registration queries, etc.)
that have, or are likely to, experience attacks or be used for
non-authorised activities. Their purpose is to validate that it is a
real person using the application – not an automated tool.
In theory, the ability to differentiate
between a real person and a tool or computer system can be done
through a specific test. These tests are often called Turing tests,
and recent work in this area has led to the development of CAPTCHA
(Completely Automated Public Turing Test to Tell Computers and
Humans Apart – http://www.captcha.net/) systems for web-based
applications.

Anti-tool Client-side Code
Whilst the techniques examined in the previous
section provide various degrees of protection against automated tool
attacks, there exists an additional array of defences capable of
defending against all but 3rd generation scanners. These additional
defences make use of client-side code.
The use of client-side code, from a security
perspective, tends to be overlooked – largely due to a poor
understanding of the different coding techniques and adverse
publicity associated with frequent client-server content validation
flaws. Although an attacker can indeed bypass client-side scripting
components that validate content or enforce a sequence of events
within the client browser fairly easily, it is still possible to use
client-side code as a positive security component as long as
suitable validation occurs at the server-side.
The Strengths of Client-side Code
As a mechanism for protecting against
automated attack tools and scanners, client-side code provides
numerous advantages over other protection mechanisms. However the
greatest advantage is derived from the fact that current automated
tools either cannot execute the code, or are extremely limited in
their ability to interpret any embedded code elements.
The trick to using client-side code in a
security context lies in ensuring that the client browser really did
execute the code (i.e. validating execution) and did not simply
ignore or bypass it. This can be achieved by forcing the client
browser to submit a unique value that can only be obtained as part
of the actual code execution. These code execution values, or
“tokens”, are submitted with any data request or submission, and
validated by the server-side application prior to the processing of
any other client-supplied data. This process can be referred to as
“tokenisation”
While the final client-side code
implementation may take on many forms, this functionality can be
achieved using any modern client-side interpreted language including
JavaScript, VBScript, Java, or even Flash. In fact, if so required,
even compiled client-side components (e.g. ActiveX) could be used so
long as the client-browser is likely to have it installed - although
this is not recommended due to probable code flexibility issues. For
ease of implementation it is recommended that client-side
interpreted languages, which are available by default within modern
client browsers, be used.
Client-side Scripting Alternatives
There are a near infinite number of ways to
utilise client-side code elements as a protection device against
automated attack tools – with each one influenced by factors such as
the nature of the web-based application (e.g. e-banking, retailing,
informational, etc.), the type of user (e.g. customer,
administrator, associate, etc.), or even the personal preferences of
the development staff.
However, there are three primary classes of client-side code
elements capable of defending against most automated attack tools:
- Token Appending.
- Token Calculator.
- Token Resource Metering.
Token Appending
The simplest of the client-side scripting
techniques, token appending makes use of pre-calculated tokens
embedded within the HTML body of the server-supplied content which
must then be appended to any data submission or request by the
client browser.
For instance, in the example below the HTML
content contains a dynamically built link that uses JavaScript to
populate the missing “token” value. Any tool that inspects the raw
HTML is likely to identify the HREF entity but fail to include the
necessary token value.

Alternatively, in the second example below, we
see a POST submission form version. A JavaScript function, “addtoken()”,
exists in the head section of the HTML document which is called from
the submission form (“myform”) with the onClick routine. By default,
the “token” field is set to “Fail” – meaning that any failure to
process the JavaScript correctly will result in a POST submission
containing the data “token=Fail” and would be interpreted by the
server-side application as a possible attack.
The only valid way of submitting data using
this form is by executing the “addtoken()” function after clicking
on the submit button. This JavaScript function then modifies the
“token” value by replacing the default “Fail” with the real value
(“0a37847ea23b984012”) and completes the submission.

The principles governing this tokenisation of
a link are very similar to those discussed in section 3.8 “Onetime
Links”, and the server-side responses to an identified attack can be
the same.

Token Calculator
Using almost identical techniques as the Token
Appending class discussed previously, the Token Calculator class
extends these principles by adding a dynamic token creation process.
Instead of using static tokens (e.g.
token.value="0a37847ea23b984012"), the client-side script
functionality is extended to include routines that actually
calculate a token from scratch. For example, in the code snippet
below, JavaScript is used to combine the “fake” default token with
the session cookie and the page name, and then calculate a CRC32
checksum – that then replaces the “fake” token – and submits the
form data to the application.

The routines used to calculate the token can
take practically any form and may be as complex or as simple as the
application developer feels comfortable with. The only limitation is
that the server-side application must be able to verify the
integrity and correctness of the token with each client browser data
request or submission. Some examples of token calculation include:
- Concatenating several text variables
embedded within the HTML document to create a single submission
token.
- Performing a mathematical routine based
upon variables embedded within the HTML document to create a
numeric submission token.
- Using HTML document properties (e.g.
session cookies, browser-type, referrer field, etc.) or other
user supplied form fields (e.g. user name, date of birth, etc.)
to create a unique submission token for that page.

Token Resource Metering
Token Resource Metering extends and refines
the principles of the Token Calculator and Token Appending
strategies by increasing the complexity of the client-side code
execution so that the client browser, when calculating the token,
incurs a measurable time delay. The calculated token forms an
“electronic payment” and can be used to slow down an automated
attack. This process of slowing down data requests or submissions is
commonly referred to as “Resource Metering”.
The trick to a successful resource metering
strategy lies in ensuring that the calculated token is easily
calculated and validated at the server-side, but requires measurable
effort to calculate at the client-side. For a full explanation of
Resource Metering and how it can be used in a security context,
readers are directed to the comprehensive paper titled “Anti
Brute Force Resource Metering”, also by the same author.

Conclusions
The use of automated tools to identify
security weaknesses within web-based applications and to attack
vulnerable content is an increasingly common practice. Therefore, it
is important that organisations take adequate precautions to defend
against the diverse range of tool techniques and increasingly
sophisticated automated scanners used by current and future
attackers.
The methods described within this whitepaper
provide varying degrees of protection against these attack tools.
Simple techniques such as changing host service names, blocking of
HTTP HEAD requests and the use of non-informative status codes
should be considered an absolute minimum for today’s environments.
More sophisticated techniques requiring tighter integration with the
dynamically generated application content help to provide better
protection, but must be factored early on into the application
development lifecycle if they are to be effective.
As the attack tools become even more
sophisticated and overcome many of the simpler defence techniques,
organisations will be forced to consider the use of client-side code
techniques. These techniques currently have the ability to stop all
of the generic automated attack tools currently available –
including most of the more sophisticated commercial vulnerability
scanners (this is important since keygen’s and license-bypass
patches are in common use).
Comparative Studies
The techniques explained within this
whitepaper for stopping automated attack tools all have their own
unique strengths and weaknesses. For an organisation seeking to
protect their web-based application from future attack, it is
important that the appropriate defensive strategy be adopted and
that the right anti-automated tool technique is applied. The
following tables help to provide a comparative study of the
different techniques previously discussed – however, it is important
that application designers realise that these comparisons are of a
general nature only (due to the phenomenal array of different
automated attack tools which are currently available).
Technique vs. Tool Generation and
Classification

Technique vs. Implementation and Client
Impact
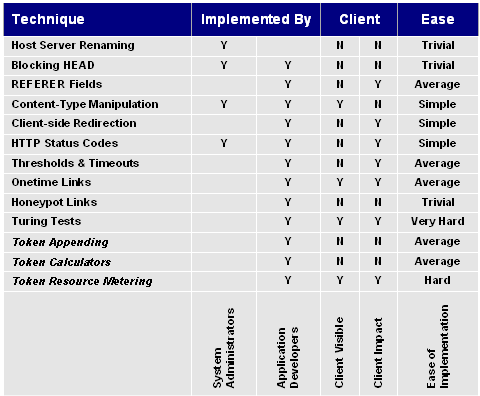
Authorised Vulnerability Scanning and
Security Testing
It is important to understand that the use of
automated attack tools play an important role in the legitimate
identification of security vulnerabilities. Organisations should be
mindful to ensure that any anti-tool defences they install can be
overcome for authorised security testing. Failure to include such a
mechanism is likely to result in extended and difficult security
assessment and penetration testing exercises, which is likely to
lead to high costs or a less thorough evaluation.
It is recommended that system administrators
and application developers provide a mechanism to turn off many of
the more sophisticated anti-automated tool defences based upon
factors such as IP address, connection interface or even reserved SessionID’s. For most of the defensive techniques discussed in this
paper, any of these mechanisms could be used. However, care should
be taken to ensure that this “bypass” mechanism is by default
switched off, and must be temporarily enabled to allow automated
security testing of the application and its hosting environment.
Combining Defence Techniques
It is important organisations design their
online web-based applications in such a manner as to take advantage
of as many of the anti-tool defensive techniques as possible. The
ability to stack and combine compatible techniques will strengthen
the application against attack – providing a valuable defence in
depth.
Custom Attack Tools
The techniques outlined in this whitepaper
provide varying degrees of defence against automated attack tools
which are available through most commercial, freeware and
underground sources. However, it is important to note that, should
an attacker seek to purposefully target an organisation and take the
necessary time and effort to fully engage or evaluate an
applications defence, it is likely that they will be able to
construct a custom automated attack tool capable of bypassing most
of them.
Organisations should evaluate the likelihood of a potential attacker
crafting a custom tool to overcome the applications anti-tool
defences and seek to adopt appropriate strategies for detecting
anomalies in application usage (e.g. repetitive data submissions,
high volumes of network traffic at odd hours from out of zone IP
addresses, repeated use of the same credit card, etc.).
|

